Big Data
Big Data has changed our concepts of Sources and Targets. What used to be relational databases, highly processed data marts, and schema-before designs has become Big Data, schema-o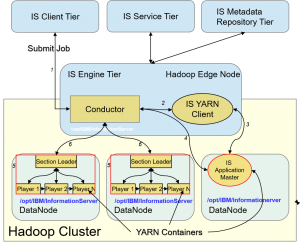 n-read, and lots of raw, unprocessed information.
n-read, and lots of raw, unprocessed information.
The Apache Hadoop storage generation has been pushed by vendors starting with Cloudera, HortonWorks, and MapR, but has been adopted by IBM, Oracle, and Teradata. Database structures such as Clementine is enjoying a surge of popularity, as well as HBase and Parquet. At the same time, similar NoSQL document stores CouchDB and MongoDB are expanding the definition of data stored.
The main business target of these installations is large relational database structures with their complex indexing and management. Many customers are trying to replace Oracle, Teradata, or DB2 installations with Hadoop or another technology. This is not a trivial project; let us help decide what should stay and what should go to avoid spinning your wheels and wasting money.
As an example, IBM Information Server has the capability to leverage existing development resources and add enterprise metadata to Hadoop processing, either from the edge node or running natively on Hadoop nodes themselves. This has the significant benefit to limit expert resources, provide an existing performant platform to load less-expensive data stores, and avoid the proliferation of hand coding that chokes development and innovation.
One of the most exciting new developments is Spark 2.0 from DataBricks. This parallel execution framework is similar to the IBM parallel framework underlying Information Server and promises to be a major player over the next few years. We can help integrate Spark with Information Server, decreasing cost, increasing innovation, and expanding your reach for business solutions.